

Peak sale hours in India — from festive campaigns to flash sales — test the resilience of payment systems like nothing else. Even minor failures during these high-volume periods can cascade into lost orders, frustrated customers, and operational chaos. For D2C brands, a failed transaction is not just a lost payment; it’s a potential breakdown across logistics, support, and customer trust.
This blog, Payment fallback strategies for failed transactions during peak sale hours, explores practical approaches for handling payment failures in real time.
We focus on strategies that preserve revenue, maintain operational flow, and keep customers informed without creating friction.
From automated retries and alternative payment routing to prioritising high-success methods and real-time alerting, these strategies are designed for scalable operational resilience.
Why payment failures spike during peak sales
Understanding system stress points is key to designing effective fallbacks
Increased transaction volume and concurrency

During peak sales, multiple users attempt payments simultaneously, often overwhelming payment gateways, banks, or internal systems. Timeouts, processing delays, and temporary failures become much more common under these conditions.
Operational impact
Even a few seconds of delay can cause failed authorisations or duplicate charges. Without fallback strategies, ops teams face higher support tickets, manual reconciliation, and potential revenue loss. Logging each failure with context is critical for prioritising intervention.
Payment method-specific vulnerabilities
Certain methods — UPI, BNPL, wallet systems, or net banking — are more prone to failures during high concurrency periods. Each has unique failure modes, such as OTP delays, session expiries, or third-party outages.
Why this matters for ops teams
Understanding the failure characteristics of each method allows ops to trigger the correct fallback action automatically, rather than relying on blanket retries that can exacerbate failures.
Mapping failure types for operational clarity
Not all failures are the same — classification enables smarter fallback strategies
Differentiating temporary vs permanent failures
Temporary failures include network timeouts, gateway latency, or retriable bank errors. Permanent failures include insufficient funds, blocked cards, or rejected BNPL applications.
Operational decision-making
Temporary failures can trigger automated retries, alternate gateways, or queued attempts. Permanent failures require alternative payment options, proactive customer messaging, and possibly manual intervention.
Categorising based on customer impact
Failures can also be segmented by their operational risk: high-value orders, first-time buyers, or premium delivery commitments require priority handling.
Example
A failed transaction for a high-value order may trigger an immediate fallback to the next available payment gateway, whereas a small, low-priority order may wait for automated retries.
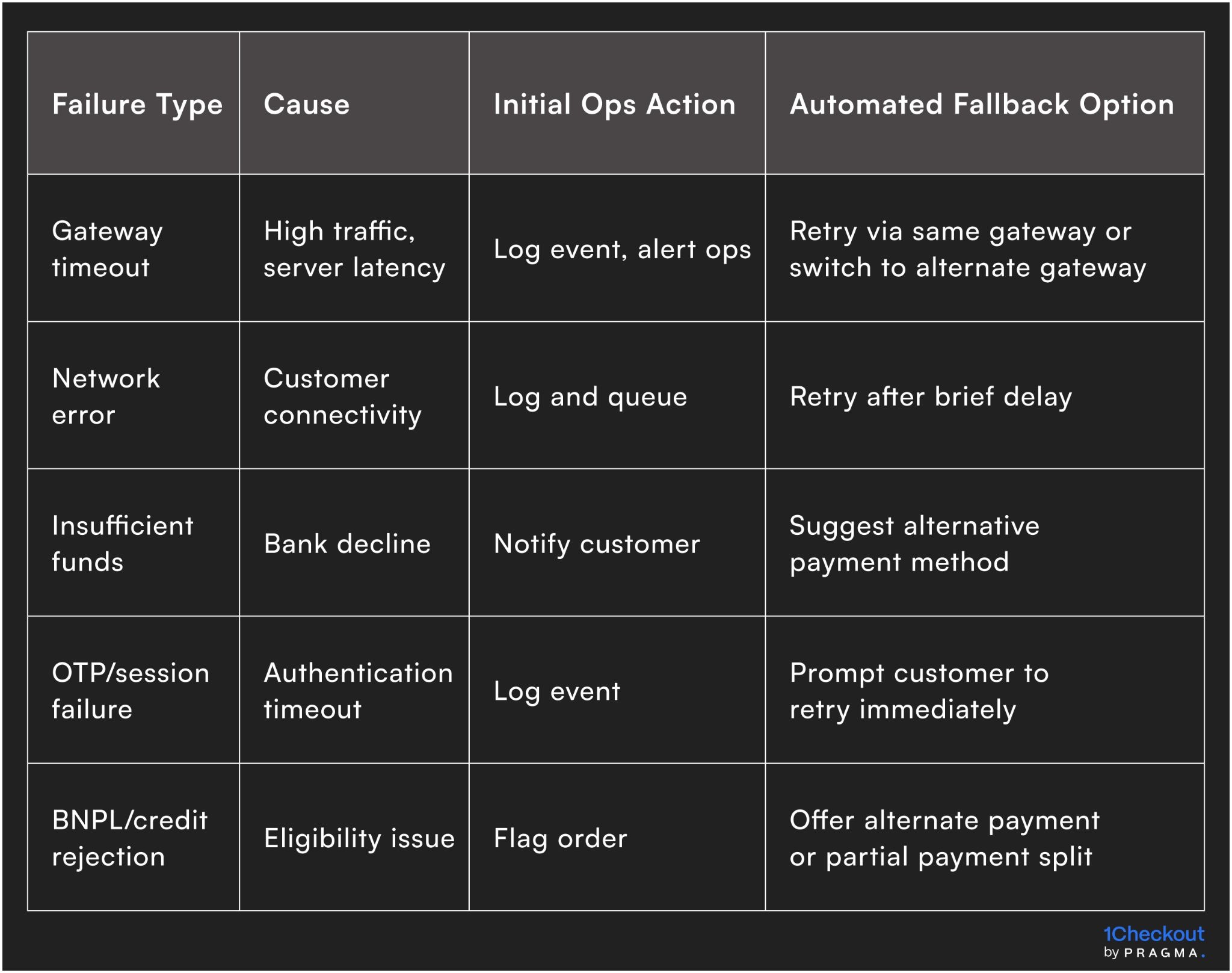
Common payment failure types and initial fallback approaches
Designing automated fallback workflows
Automating responses reduces operational friction and revenue loss
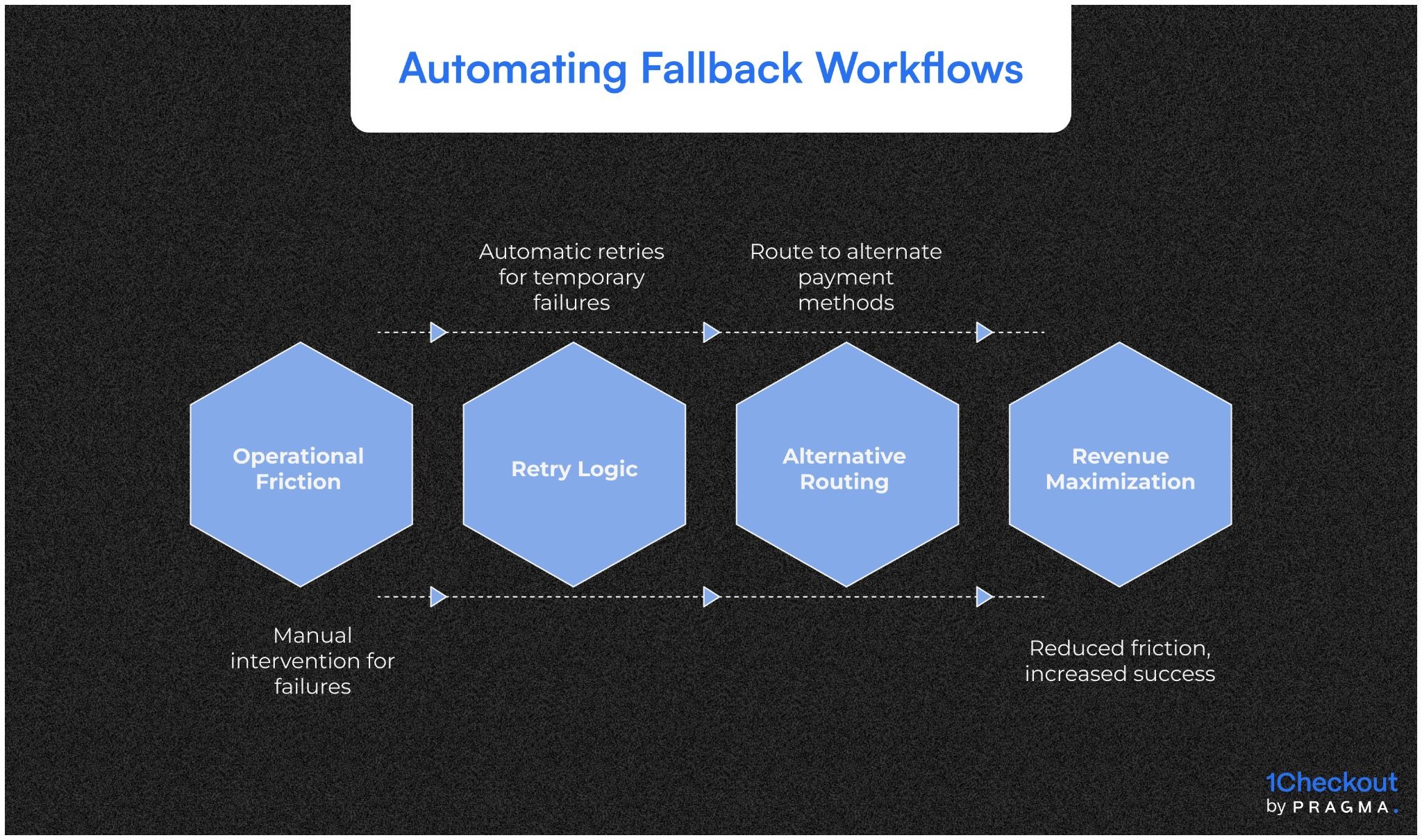
Retry logic for temporary failures
Temporary failures, like network timeouts or gateway latency, should trigger automatic retries based on predefined intervals. Ops teams must ensure retries do not overload the gateway further, so exponential backoff or queued retries are critical.
Operational impact
Automated retries prevent manual intervention for high-volume orders while maximising transaction success. Logging each retry attempt allows ops teams to detect patterns and address systemic issues quickly.
Alternative payment routing
For both temporary and permanent failures, routing to alternate payment methods or gateways ensures continuity. High-priority or high-value transactions should have preconfigured alternate pathways to prevent revenue loss.
Implementation example
If a customer’s UPI transaction fails during peak traffic, the system can automatically attempt an alternate gateway or suggest wallet/net-banking options without manual input.
Escalation and alerting for persistent failures
Fail-safes ensure operations teams intervene before issues affect customers
Alerting ops teams for repeated failures
When automated retries fail multiple times, the system must log escalation events and notify ops teams. Alerts should contain sufficient context: payment method, transaction amount, user segment, and failure type.
Operational benefits
Timely alerts prevent revenue leakage, reduce customer complaints, and allow targeted intervention for high-value transactions. This also supports post-mortem analysis for system improvements.
Customer-facing fallback notifications
Persistent failures require clear, actionable communication to customers. Proactive notifications reduce frustration and support tickets, guiding users to alternate methods without delay.
Example
An SMS or in-app message indicating a payment failure with suggested alternatives can improve completion rates while maintaining trust during peak sale hours.
Multi-gateway orchestration for higher payment success rates
Distributing risk across providers to ensure transaction continuity
Relying on a single payment gateway during peak sale hours introduces a critical point of failure. Multi-gateway orchestration ensures that transactions are dynamically routed based on performance, availability, and success probability.
Dynamic gateway selection
Instead of statically assigning a gateway, systems should evaluate real-time performance metrics such as success rate, latency, and failure patterns. Transactions can then be routed to the most reliable gateway at that moment.
This reduces dependency on any single provider and improves overall success rates during high concurrency.
Load balancing during peak traffic
Payment traffic can be distributed across multiple gateways to prevent overload on any single system. By spreading transaction volume intelligently, brands reduce timeout errors and maintain consistent performance even during traffic spikes.
Failover mechanisms
When a gateway experiences downtime or increased failure rates, automatic failover ensures that transactions are rerouted instantly without user intervention.
For example, if a primary gateway fails during a flash sale, secondary gateways can take over seamlessly, preventing revenue loss and maintaining checkout continuity.
Operational visibility
Multi-gateway setups require strong monitoring systems. Ops teams must track gateway-level metrics in real time to identify underperformance and adjust routing rules dynamically.
This visibility ensures that fallback decisions are data-driven rather than reactive.
Outcome
Multi-gateway orchestration transforms payment systems from fragile, single-point dependencies into resilient, adaptive infrastructures capable of handling peak sale volatility.
Optimising checkout UX to reduce payment drop-offs during failures
Designing frictionless recovery paths within the payment experience
Payment fallback strategies are only as effective as the customer experience they sit within. During peak sale hours, even a well-configured backend fallback can fail if the checkout interface creates confusion or friction after a transaction failure.
Seamless retry experience within checkout
When a payment fails, customers should not be forced to restart the entire checkout process. Preserving cart details, address information, and selected payment methods ensures continuity.
A well-optimised checkout automatically prompts users with a clear retry option, pre-filled details, and minimal steps. This reduces abandonment rates, especially during high-intent peak sale moments where even small delays can cause drop-offs.
Smart payment method reordering
Checkout interfaces should dynamically reorder payment options based on real-time success rates. For example, if UPI failures spike during peak load, more reliable methods like cards or wallets can be surfaced higher in the payment stack.
This subtle optimisation significantly improves conversion without requiring explicit customer decision-making under pressure.
Contextual error messaging
Generic error messages like “Transaction failed” increase confusion and retries on already failing methods. Instead, error prompts should be specific and actionable:
- Suggest switching payment methods
- Indicate if the issue is temporary
- Provide reassurance about duplicate charges
Clear messaging reduces panic, improves trust, and guides customers toward successful completion.
Outcome
By aligning checkout UX with fallback logic, brands can convert failed payment attempts into completed transactions without increasing operational burden or customer frustration.
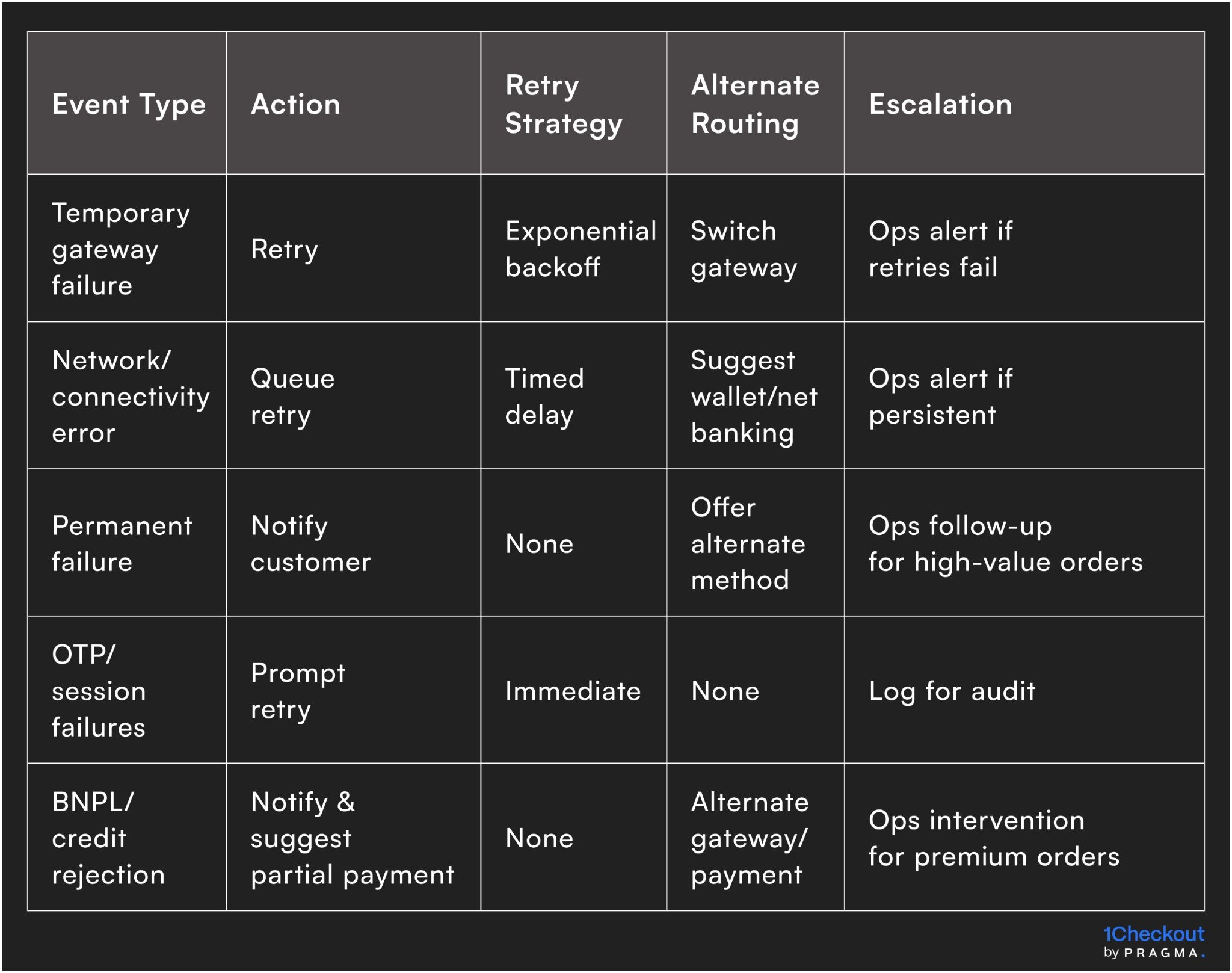
Automated fallback workflow framework
Quick Wins on implementing payment fallback strategies
Practical steps for operations teams during peak sale hours
Week 1 – Audit past failures
Identify top failure types from previous peak sales. Categorise by temporary vs permanent and high vs low impact.
Week 2 – Implement automated retries
Set up retry logic for temporary failures with exponential backoff. Ensure logging captures each attempt.
Week 3 – Configure alternate payment routing
Predefine backup gateways or payment methods for high-value or high-priority transactions. Integrate automatic switching.
Week 4 – Set up alerting and customer notifications
Create escalation alerts for persistent failures and automated customer messages to guide them to alternative payment options.
Pre-emptive failure prevention before transactions break
Reducing fallback dependency by addressing risks upfront
While fallback strategies are essential, the most efficient operations reduce the likelihood of failures before they occur. Pre-emptive optimisation ensures smoother payment flows and minimises the need for recovery interventions.
Monitoring bank and gateway health signals
Real-time monitoring of bank downtimes, gateway latency, and third-party outages allows systems to proactively adjust payment flows.
For instance, if a specific bank is experiencing issues, transactions linked to that bank can be deprioritised or redirected automatically before failure occurs.
Payment method throttling
During extreme peak loads, certain payment methods may become unstable due to high concurrency. Throttling limits the number of transactions routed through these methods, preventing system overload and cascading failures.
This ensures overall system stability rather than maximising usage of a failing channel.
Intelligent transaction queuing
Instead of allowing all transactions to hit the gateway simultaneously, queuing mechanisms can stagger requests to reduce load. This prevents timeouts and improves success rates without requiring customer intervention.
Aligning payment availability with logistics capacity
High payment success without operational readiness can create downstream issues. Aligning payment acceptance with inventory, fulfilment capacity, and delivery readiness ensures that successful transactions can be fulfilled without delays or cancellations.
Outcome
Pre-emptive strategies reduce the frequency and severity of payment failures, allowing fallback mechanisms to operate as a safety net rather than a primary dependency.
Metrics to track for payment fallback strategies
Ensuring operational effectiveness and revenue protection during peak sales

Monitoring these metrics ensures that fallback strategies not only recover revenue but also maintain operational visibility and customer trust during peak load periods.
To Wrap It Up
Payment fallback strategies are critical operational levers for D2C brands during peak sale hours. Proper logging, automated retries, alternate routing, and timely escalation help teams maintain revenue, reduce manual firefighting, and preserve customer trust.
This week, audit past payment failures and implement automated retries and alternate routing for temporary and high-value order failures.
Over the long term, maintain comprehensive post-order logging, monitor metrics for success and exceptions, and continuously refine fallback logic to handle peak traffic without operational disruption.
For D2C brands seeking robust payment reliability during high-volume sales, Pragma’s payment orchestration platform provides automated fallback, real-time alerts, and event-driven analytics that help brands minimise failed transactions, maximise conversions, and maintain customer trust.
.gif)
FAQs (Frequently Asked Questions On Checkout instrumentation: the key events operations teams must log post-order)
1. Why do payment failures spike during peak sales?
High transaction volume, concurrency, and method-specific vulnerabilities cause gateway timeouts, network errors, and authentication issues.
2. What is the difference between temporary and permanent failures?
Temporary failures can be retried automatically (e.g., timeouts, network issues), while permanent failures require alternative payment methods (e.g., insufficient funds, BNPL rejections).
3. How can automated fallback routing improve conversion?
By automatically switching failed transactions to alternate gateways or methods, customers complete orders without friction, reducing revenue loss.
4. When should operations teams intervene manually?
Manual intervention is needed if retries and alternate routing fail, especially for high-value or priority transactions.
5. How do fallback strategies improve customer experience?
Proactive retries, alternate routing, and clear notifications reduce failed payments, prevent frustration, and maintain trust during peak hours.



