

Checkout success doesn’t end when the payment goes through. For operations teams, the real work begins after the order is placed, when data gaps can quietly turn into fulfilment delays, support escalations, and broken delivery promises. Many brands track checkout conversions obsessively, yet fail to instrument the post-order events that determine whether an order is actually delivered smoothly.
This blog, Checkout instrumentation: the key events operations teams must log post-order, focuses on the operational blind spots that emerge once an order leaves the checkout page. It explains which events must be captured, why they matter, and how they connect downstream to logistics, support, finance, and customer communication.
The emphasis is practical. We look at post-order instrumentation not as analytics overhead, but as operational insurance. When teams log the right events at the right time, they gain early warning signals, reduce firefighting, and build reliable customer experiences — even as order volumes and complexity scale.
Why post-order checkout instrumentation is an operations problem
Conversion success masks fulfilment risk once the order leaves checkout
Checkout completion creates false confidence
When an order is marked “successful” at checkout, most dashboards celebrate conversion and move on. For operations teams, this is often the most dangerous moment.
Payment success does not guarantee inventory availability, address accuracy, or delivery feasibility. Yet downstream systems frequently assume the order is ready for fulfilment without validating these assumptions.
This gap between perceived success and operational readiness is where most preventable failures originate. Orders move forward with hidden defects, only to break later when fixes are expensive, customer-facing, and reputation-damaging.
What breaks when post-order events aren’t logged
Without post-order instrumentation, ops teams discover problems reactively — through support tickets, failed pickups, or delivery escalations. By the time an issue surfaces, multiple teams are already involved, refunds may be triggered, and customer trust is eroded. Instrumentation shifts detection upstream, where intervention is still cheap and controlled.
Defining the post-order event boundary
Understanding where checkout truly ends and operations begins
“Order placed” is a sequence, not a state
Most systems emit a single order_placed event, but operationally this is misleading. An order transitions through multiple post-payment steps: payment authorisation, fraud checks, inventory reservation, address validation, and promise confirmation. Treating this as a single moment hides partial failures and race conditions between systems.
Each of these steps has different owners, latencies, and failure modes. Instrumentation must reflect this reality rather than collapsing everything into one optimistic signal.
Why ops teams need step-level visibility
When an order stalls or fails, ops teams need to know which step failed and why. Step-level events allow targeted intervention — rerunning a payment capture, switching inventory sources, correcting an address — instead of cancelling the entire order blindly.
Core post-order events every operations team must log
The minimum event set that enables fulfilment control
Payment finalisation and settlement events
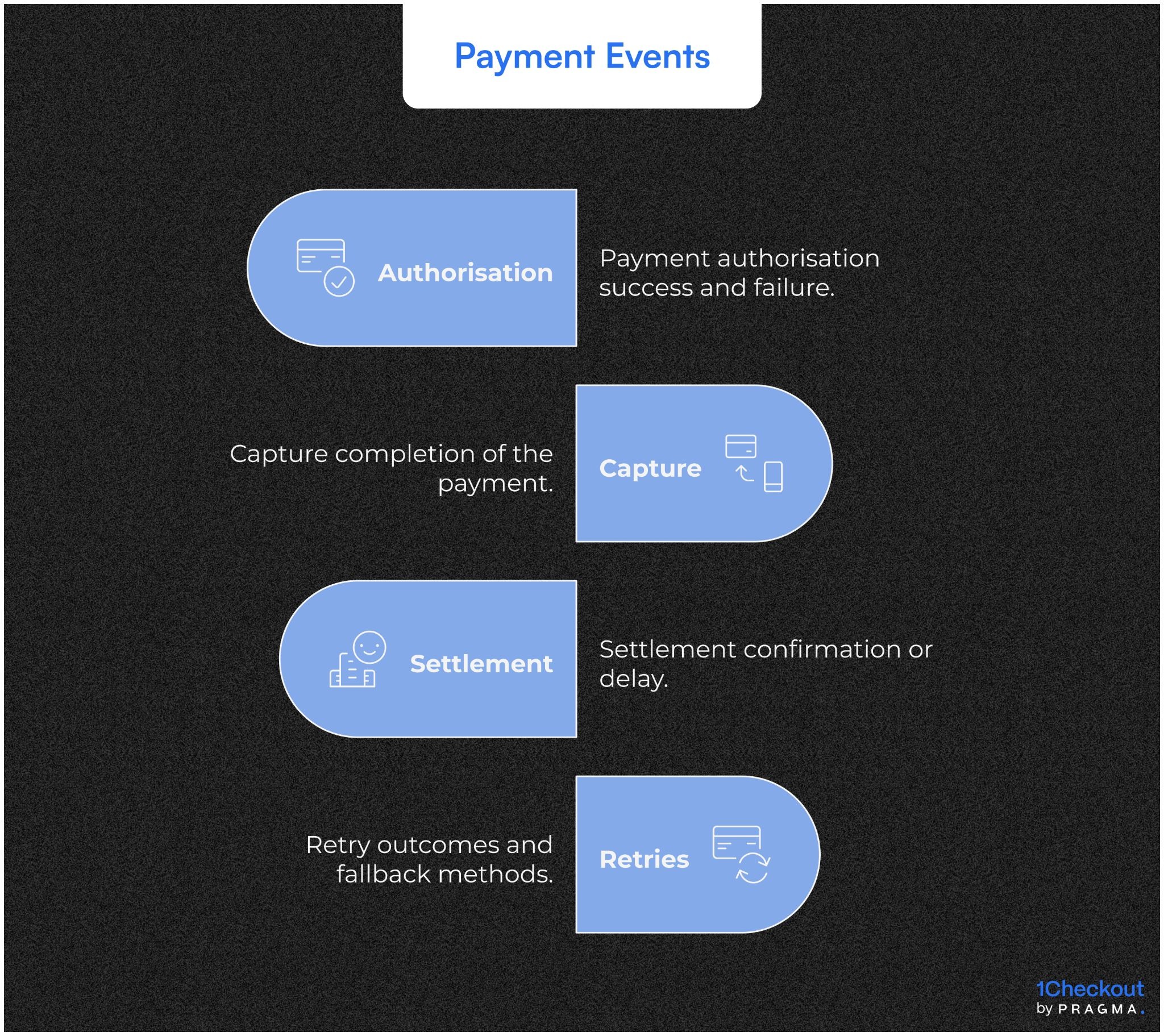
Payment success at checkout often means authorisation, not settlement. UPI delays, BNPL approvals, partial captures, and retries are common in India. If fulfilment begins before payment is truly finalised, brands risk shipping unpaid orders or creating reconciliation chaos later.
Post-order instrumentation must log:
- Authorisation success and failure
- Capture completion
- Settlement confirmation or delay
- Retry outcomes and fallback methods
Operational downstream impact
These events inform fulfilment eligibility, COD conversion logic, fraud review queues, and finance reconciliation. Without them, teams rely on assumptions that break under scale.
Inventory commitment and reservation confirmation
Checking inventory during checkout is not the same as reserving it. High-volume systems, parallel orders, and delayed warehouse syncs often cause inventory drift between checkout and picking.
Ops teams must log a hard inventory commitment event that confirms:
- SKU reserved
- Location allocated
- Quantity locked
Why “soft checks” fail during peaks
During sales or flash events, soft inventory checks lead to over-selling. By the time picking begins, inventory is already gone. Explicit reservation events give ops teams a clear gate: no reservation, no fulfilment.
Address validation and delivery promise verification
Preventing avoidable downstream failures before fulfilment starts
Address validation outcomes post-order
Checkout address entry confirms form completion, not deliverability. Post-order systems must validate:
- Pincode serviceability
- Address normalisation success
- Carrier compatibility
- Manual review flags
These outcomes should be logged explicitly, not inferred later from delivery failure.
Operational value of early address signals
Catching address issues before label generation saves courier costs, reduces RTO, and avoids customer frustration. It also enables proactive correction workflows instead of reactive apology messages.
Delivery promise confirmation and reconciliation
Delivery promises often change after checkout due to inventory reallocation, carrier constraints, or cut-off misses. If this adjustment is not logged as a distinct event, customer communication becomes inconsistent across channels.
Why ops must own promise instrumentation
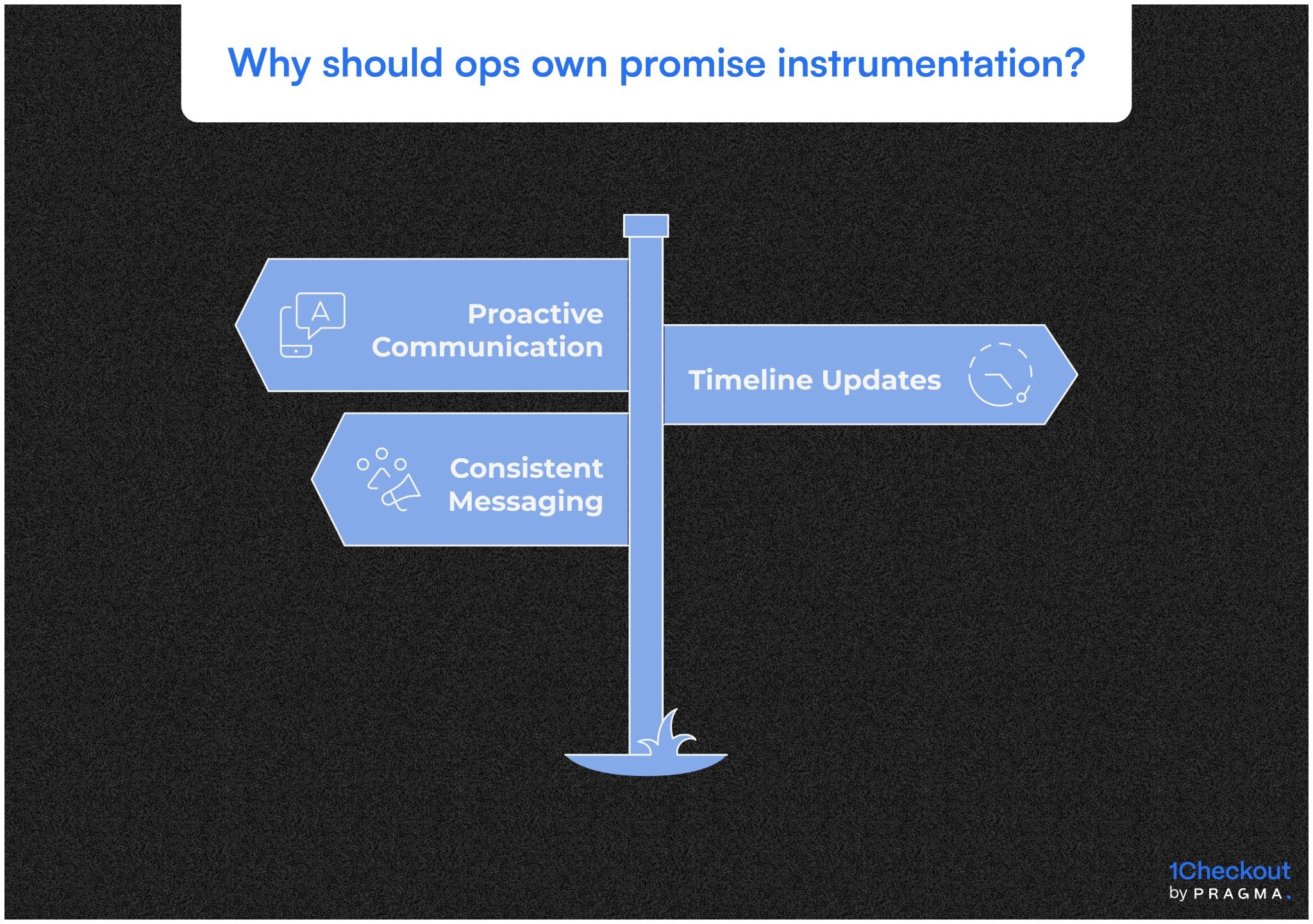
Promise confirmation events allow ops teams to:
- Trigger proactive customer communication
- Update tracking timelines
- Prevent conflicting messages on WhatsApp, SMS, and order pages
Without this, brands face the classic “but your message said…” escalation.
Exception and failure events ops teams cannot afford to miss
Failures are inevitable — blind failures are not
Why exception events matter more than success events
Most systems log success by default and treat failures as edge cases. For operations, this is backwards. Exceptions are where cost, customer dissatisfaction, and escalation originate. If failure events are not explicitly logged, ops teams only discover issues after fulfilment breaks or customers complain.
Exception events should be treated as first-class operational signals, not error logs buried in engineering dashboards.
Operational cost of silent failures
Silent failures lead to duplicate fulfilment attempts, incorrect refunds, and delayed customer communication. Each unlogged exception compounds downstream effort across support, logistics, and finance, turning a recoverable issue into a multi-team fire drill.
Payment and fraud exception events
Post-order payment issues are common, especially with asynchronous methods. Ops teams must log:
- Payment capture failure
- Settlement timeout
- Fraud review triggered
- Fraud rejection post-authorisation
These are not rare edge cases in India — they are daily operational realities.
Why ops needs explicit payment exceptions
Without explicit payment exception events, orders may proceed to fulfilment incorrectly or sit in limbo. Clear signals allow ops to pause, reroute, or cancel orders deliberately instead of discovering issues during reconciliation.
Inventory and fulfilment readiness exceptions
Inventory reservation failures, location mismatches, or picking constraints must be logged immediately once detected.
Examples include:
- Reservation failure after checkout
- SKU unavailable at assigned warehouse
- Allocation fallback triggered
Preventing downstream waste
Early inventory exception logging prevents unnecessary label creation, courier booking, and warehouse effort. It also allows intelligent rerouting rather than last-minute cancellations.
Cross-team handoff events that keep systems aligned
Instrumentation is the glue between teams
Handoff events between checkout and fulfilment
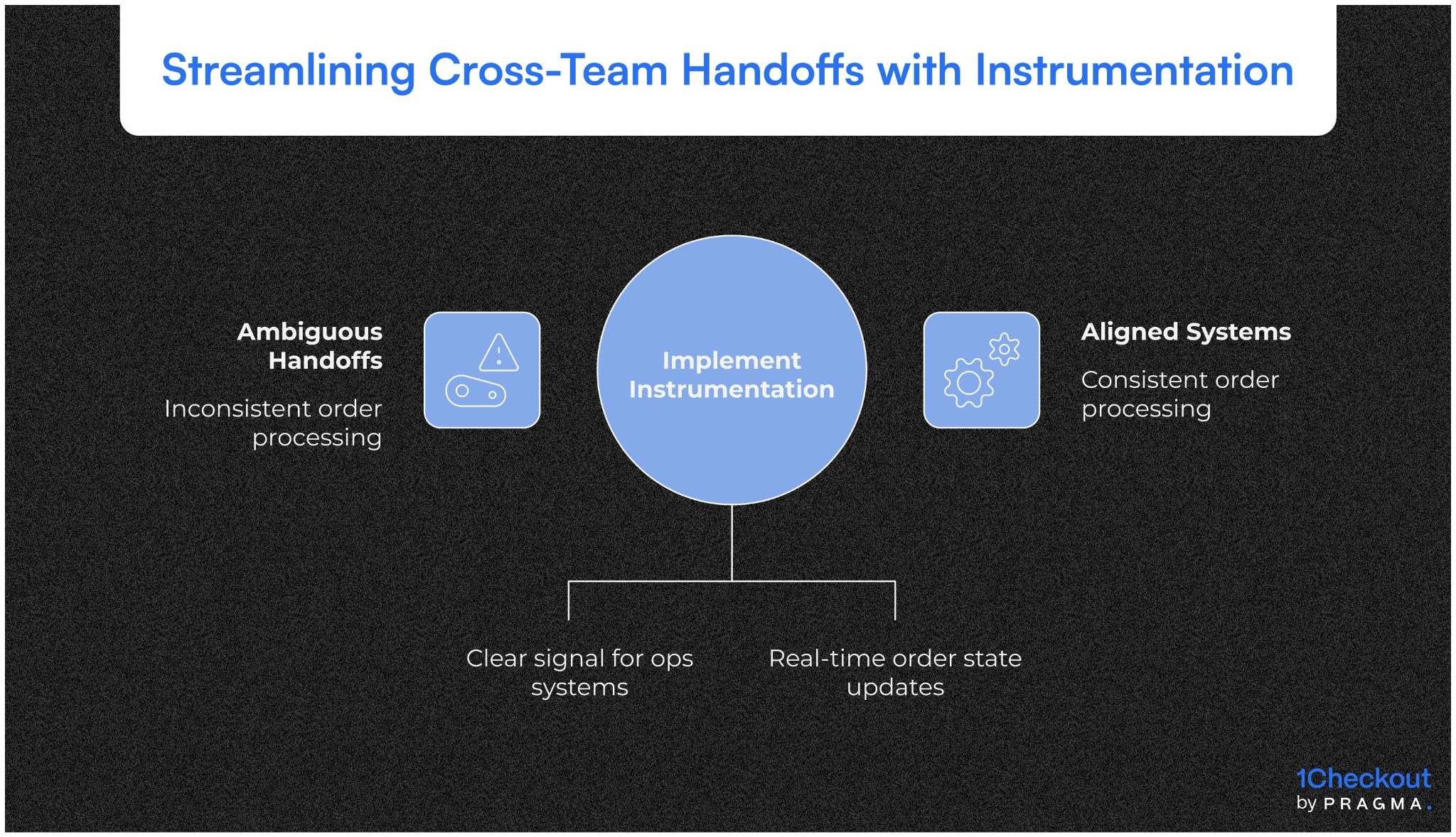
Once post-order checks pass, a clear handoff event should signal that the order is fulfilment-ready. This event acts as a contractual boundary between commerce systems and ops systems.
Why ambiguity breaks scale
If fulfilment systems infer readiness instead of receiving a clear signal, orders move forward inconsistently. Explicit handoff events reduce interpretation and enforce discipline across teams.
Ops-to-support visibility events
Support teams need visibility into post-order states without reverse-engineering logs. Events such as:
- Order blocked pending address correction
- Payment under review
- Promise revised
must be consumable by support systems in real time.
Reducing avoidable escalations
When support can see why an order is delayed, they respond with confidence instead of deflection. This reduces repeat contacts and improves customer trust.
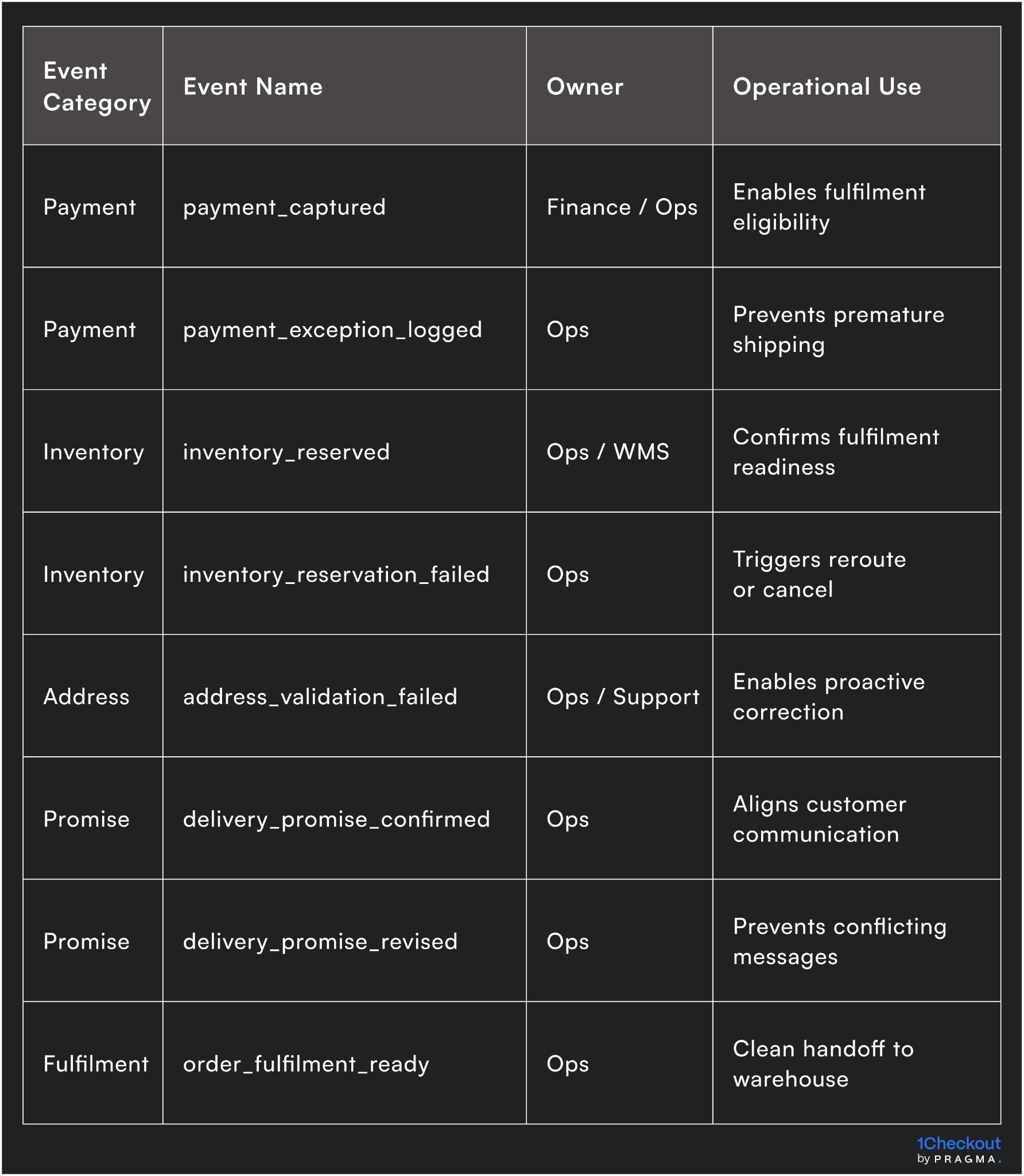
Post-order checkout instrumentation event framework
Quick wins on implementing post-order checkout instrumentation
How to gain operational control in 30 days
Week 1 – Audit post-order blind spots
List all events emitted after checkout today. Identify where systems assume success instead of confirming it explicitly.
Week 2 – Define a minimum ops event set
Agree on a non-negotiable list of post-order events that gate fulfilment, payment, and communication. Document owners for each event.
Week 3 – Instrument exceptions before optimising success
Log failure and exception events first. These deliver immediate operational value even before full success-path instrumentation is complete.
Week 4 – Expose events to support and ops dashboards
Ensure events are visible beyond engineering logs. Ops and support teams must consume these signals in real time.
Metrics to track for post-order checkout instrumentation
Monitoring ensures operational health and customer experience
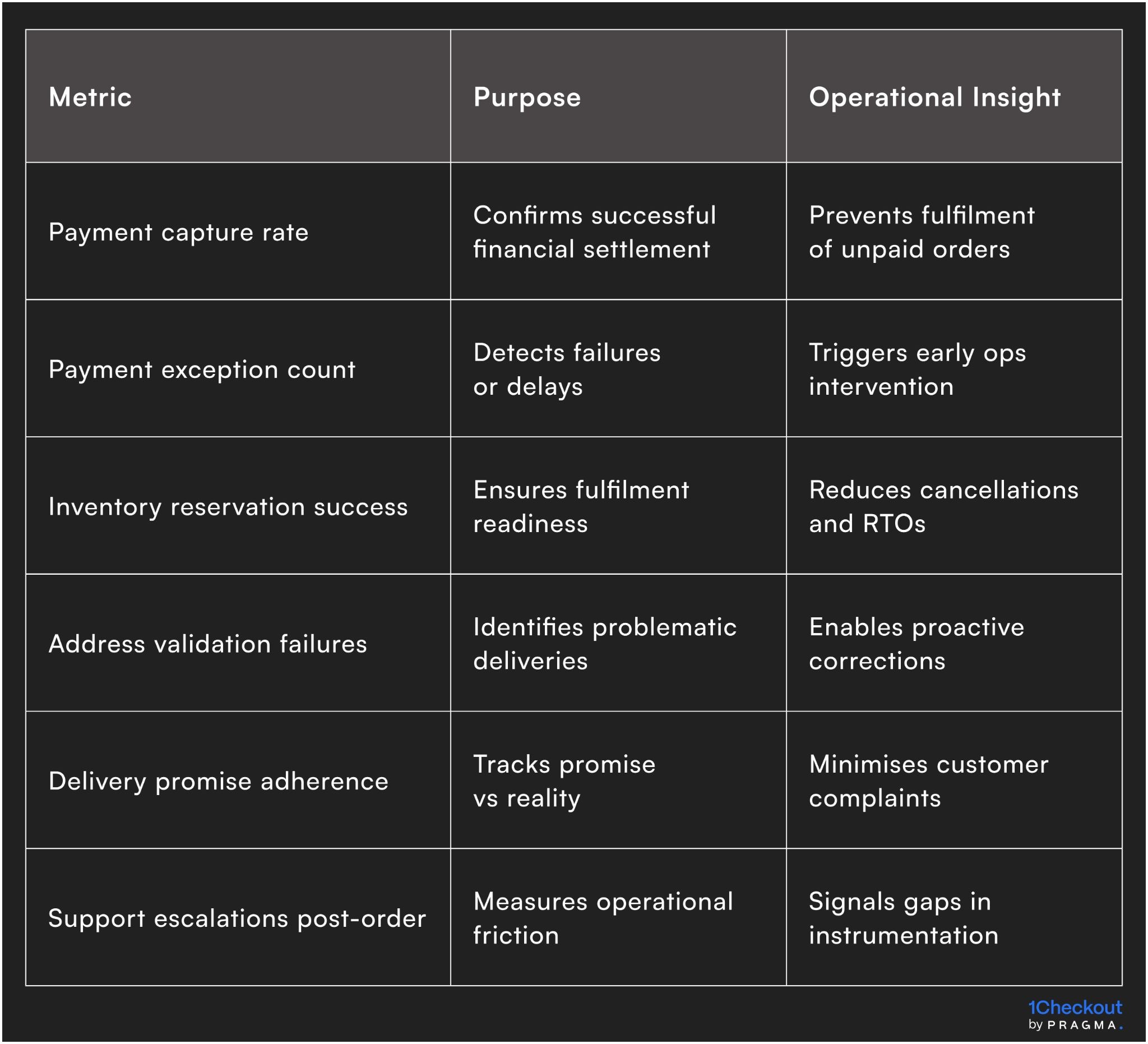
Tracking both success and exception events allows ops teams to intervene early, maintain workflow consistency, and prevent small post-order issues from becoming costly customer-facing problems.
To Wrap It Up
Post-order checkout instrumentation transforms operations from reactive firefighting to proactive control. By logging success and exception events at every critical step — payment, inventory, address, and delivery promise — teams gain real-time visibility, reduce errors, and maintain consistent customer experiences.
This week, audit your current post-order events and implement logging for payment capture, inventory reservation, and address validation.
Over the long term, maintain a robust post-order event framework, integrate dashboards for ops and support, and continuously monitor exceptions to improve scalability and reliability.
For D2C brands seeking operational excellence post-checkout, Pragma’s operations orchestration platform provides event tracking, real-time dashboards, and automated exception alerts that help brands reduce errors, improve fulfilment, and deliver seamless customer experiences.
.gif)
FAQs (Frequently Asked Questions On Checkout instrumentation: the key events operations teams must log post-order)
1. What is the difference between checkout success and post-order readiness?
Checkout success confirms payment intent, whereas post-order readiness verifies inventory, address, payment settlement, and promise feasibility.
2. Which post-order events are most critical for operations?
Payment capture, inventory reservation, address validation, delivery promise confirmation, and any exception events that block fulfilment.
3. How can operations teams reduce manual interventions post-order?
By logging events at each critical step and consuming them in real-time dashboards for proactive actions.
4. Do we need to instrument every exception immediately?
Prioritise high-impact events first, such as payment failures, inventory issues, and address problems, then gradually expand coverage.
5. How does this help customer experience?
Early detection of exceptions allows proactive communication, reducing failed deliveries, support escalations, and negative reviews.



